网站模板扒皮器 是我们独立研发的一款基于linux系统的用来快速仿制某个网站模板的神器!它能够快速高效的精仿网站的模板出来,仅需导入目标网址url,系统自动会下载出html页面以及相应的css、js、pic数据存入对应的风格文件夹内,实现快速大量制作网站模板。。。还原度非常好,基本上实现完美比例仿制。
网上能找到的模板采集软件基本上不能完美的下载所有的文件,重点是css和js内部的元素不能扣下来,做不到精仿效果,所以决定单独写个程序出来,,,
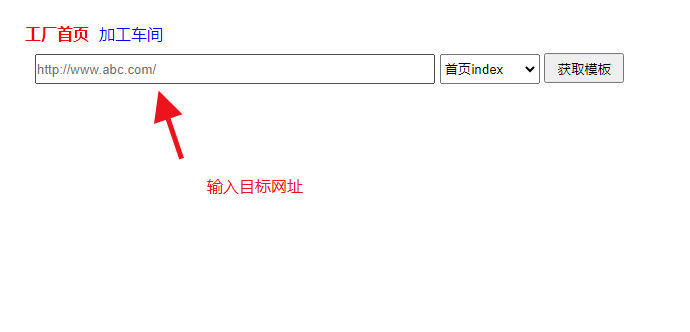
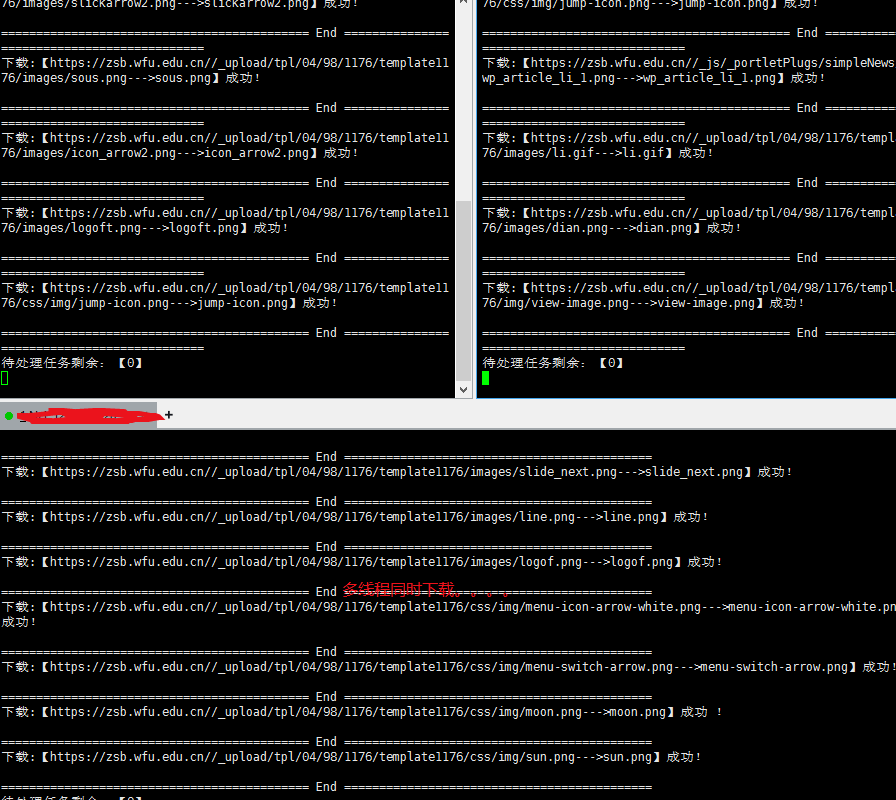
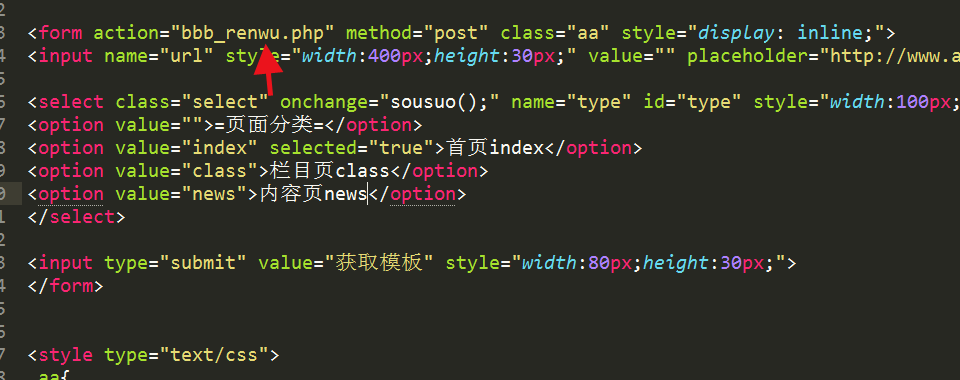
我们随便百度搜个网站去试验下,先弄首页,再弄栏目页再弄内页一共采集3个页面,
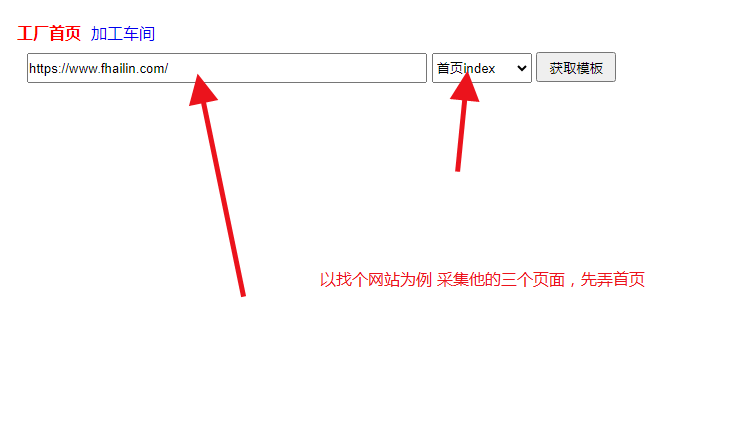
随便找个网站试试,点击采集
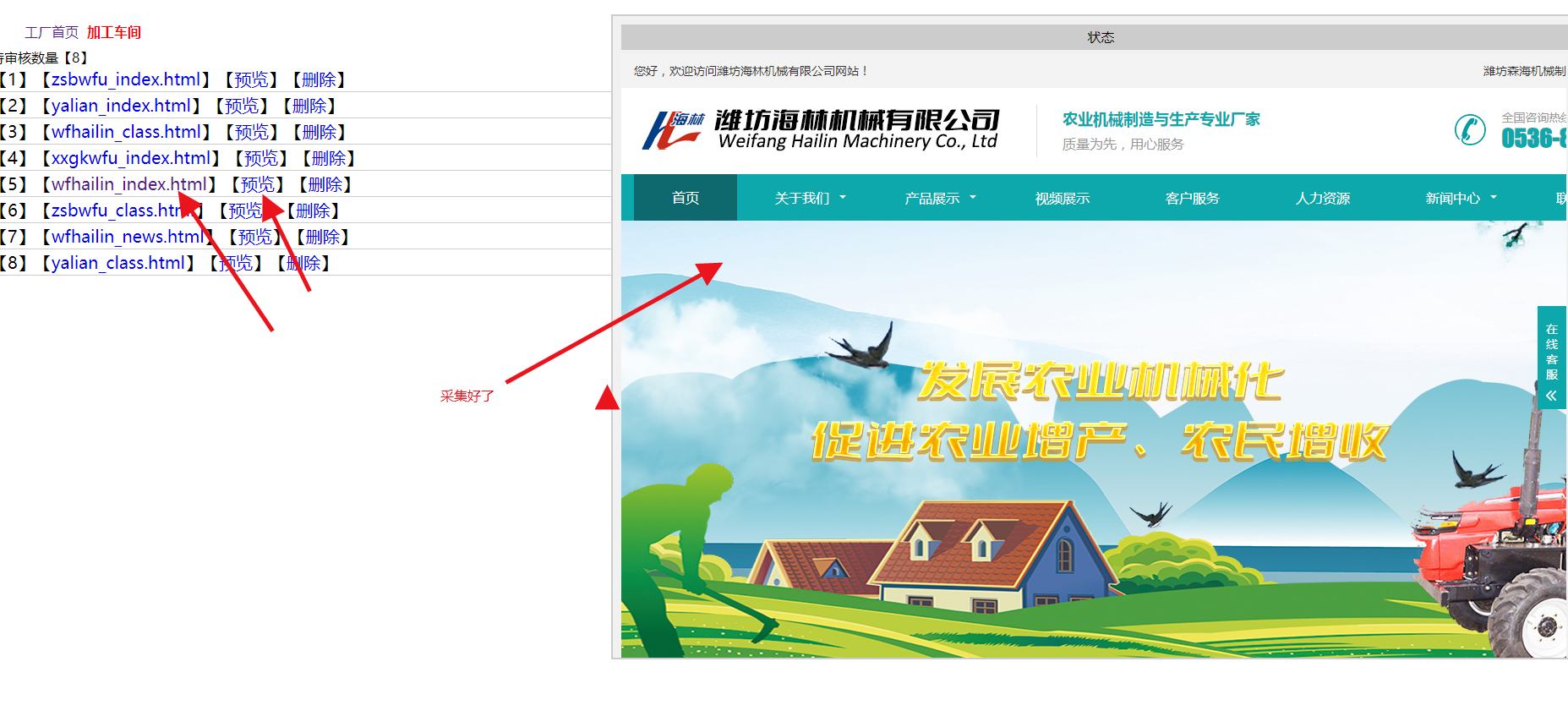
然后等一会,在“模板车间”就可以看到我们采集好的模板了。。。。可以预览,也可以打开直接看。
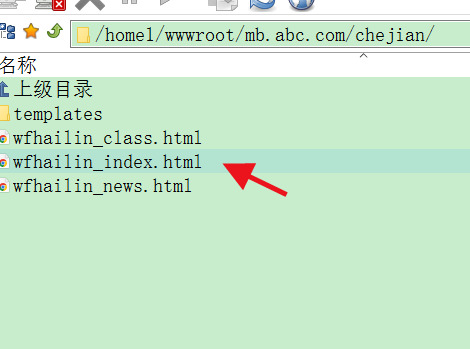
最终的文件格式是这样的
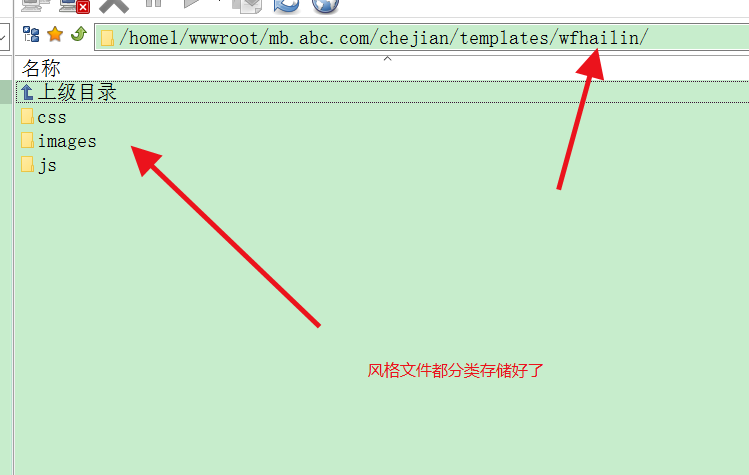
风格的路径一般就是图片、css和js,顶多有个fonts
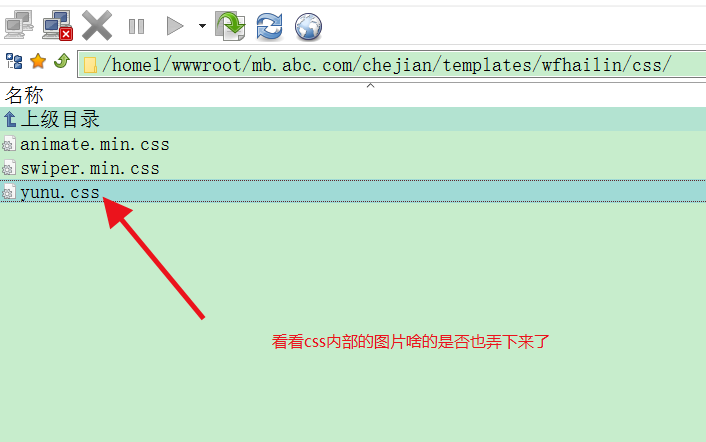
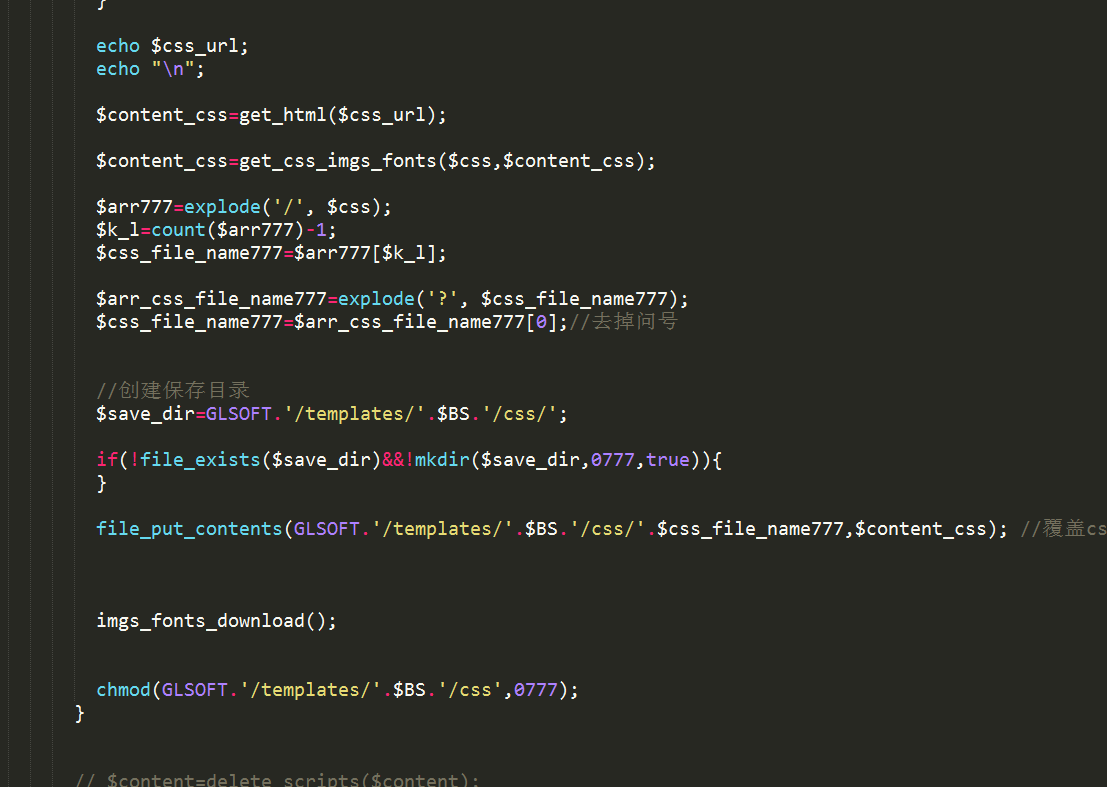
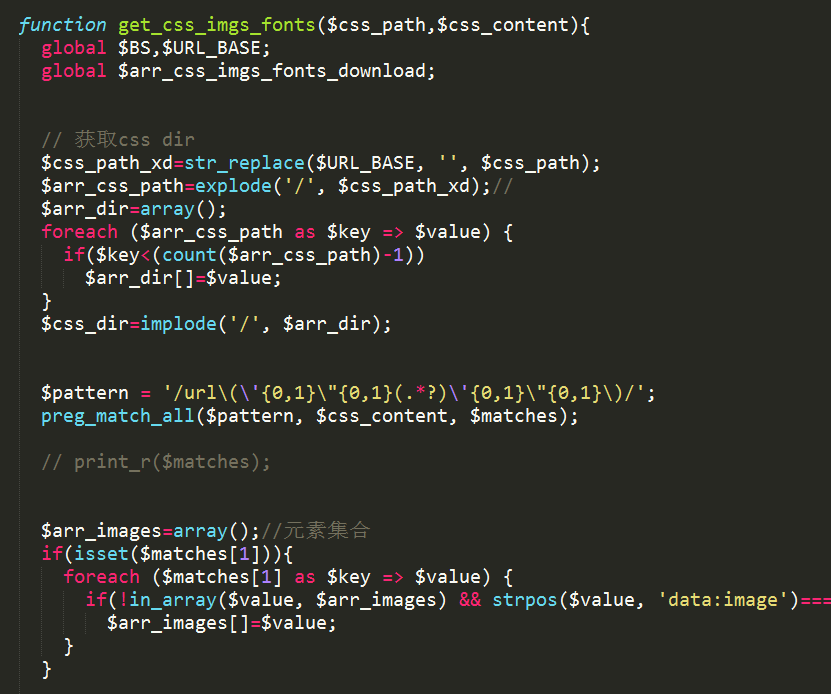
我们仔细看看css内部的background url是不是也扣下来了,
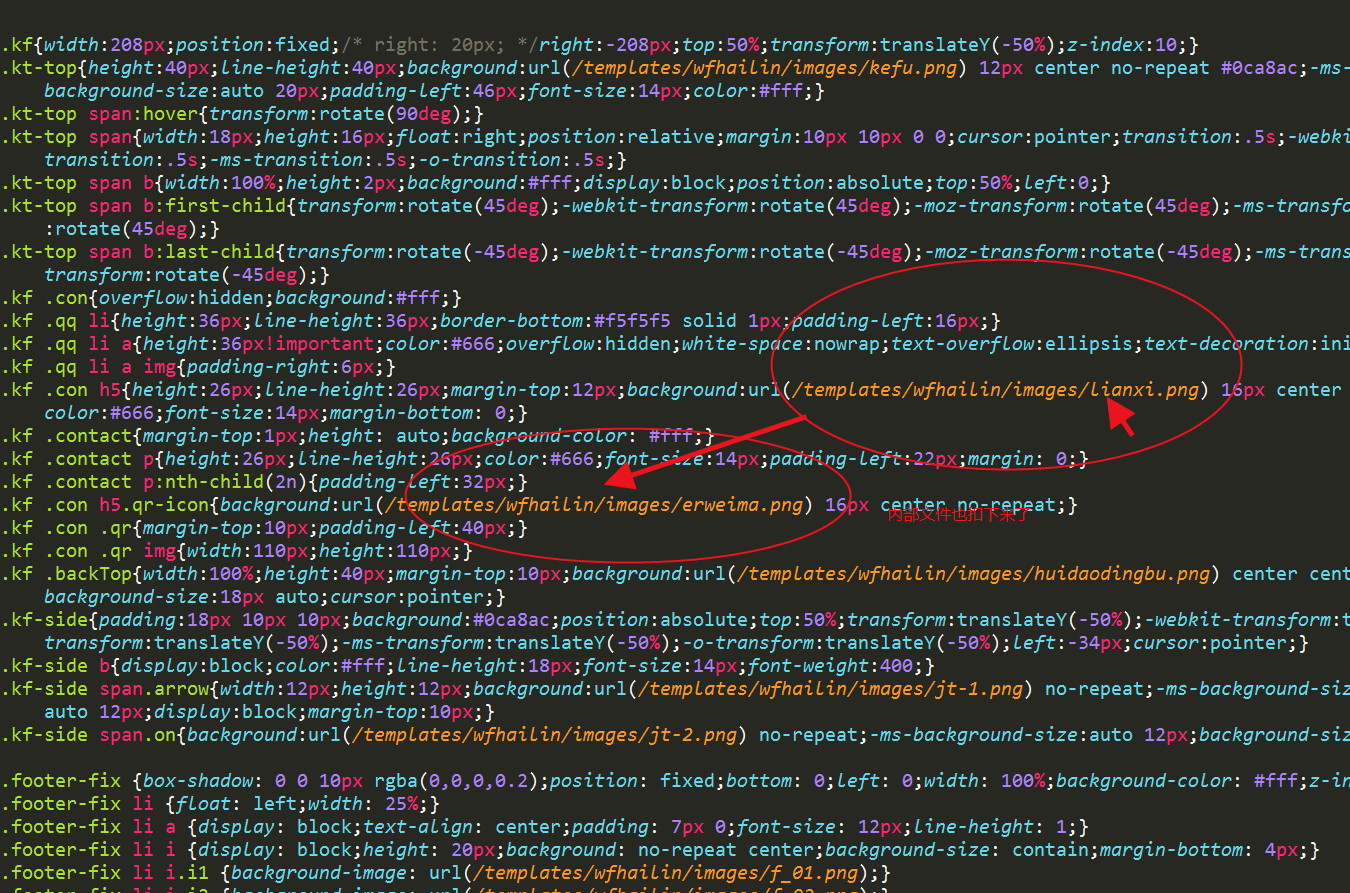
从css文件看背景图片已经替换成我们目标的路径了
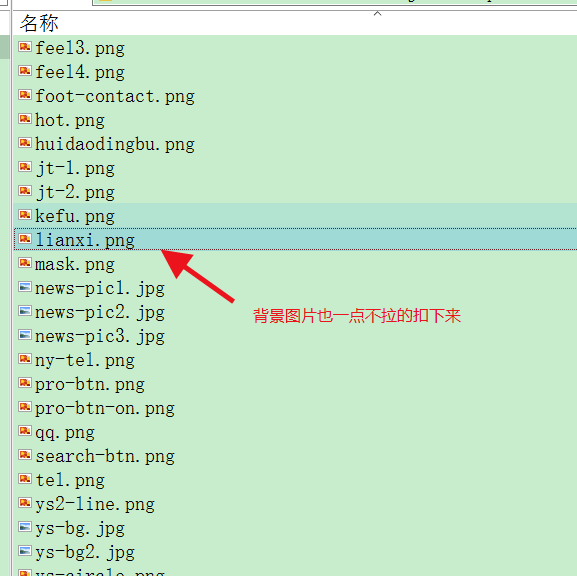
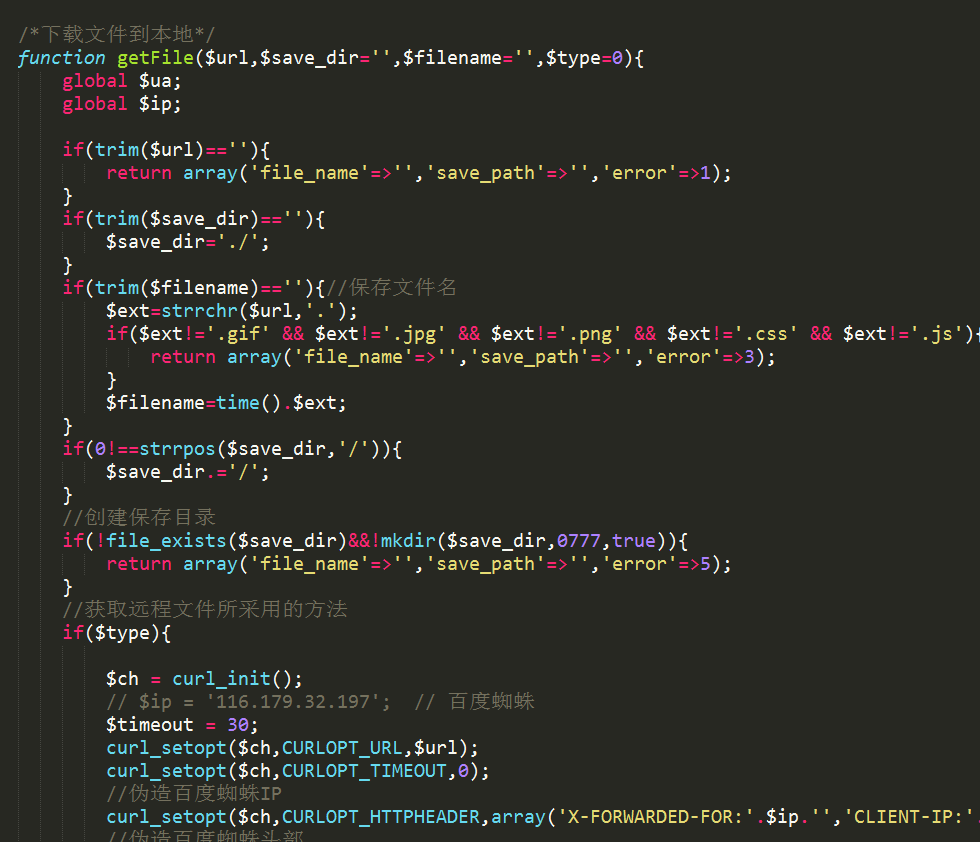
图片也真实的下载下来了
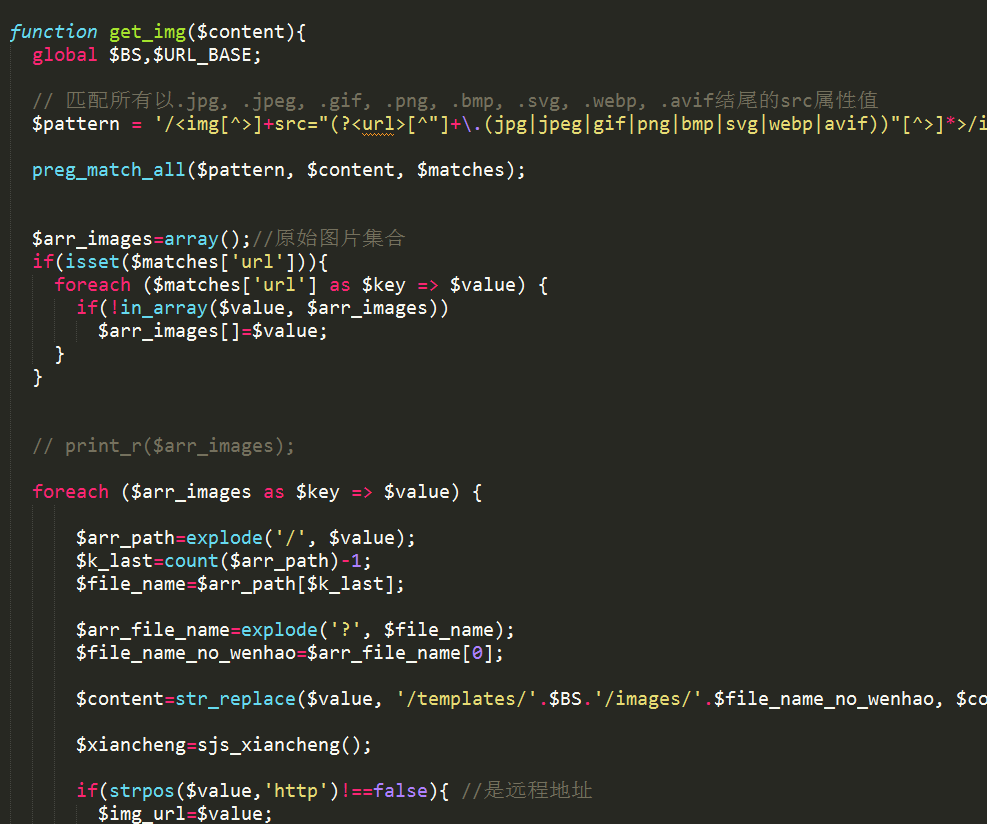
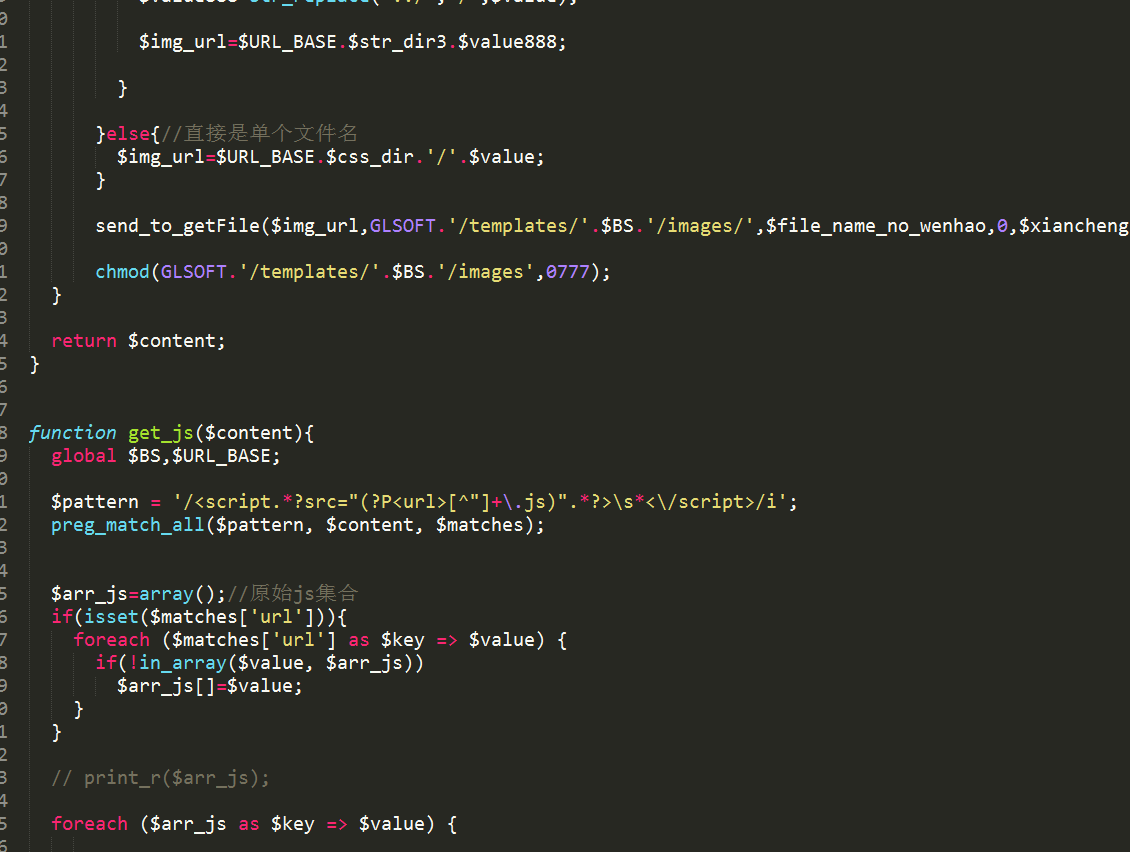
以上展示了操作下载一个网站模板的过程,那么这个程序实现的原理是啥呢?
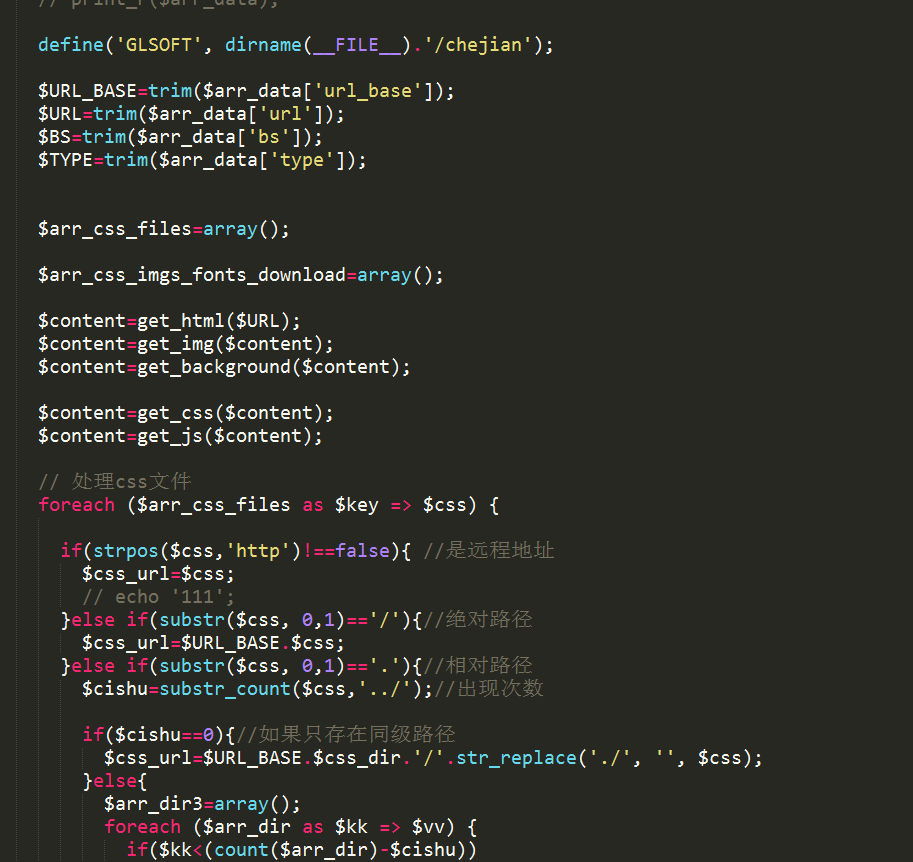
一个网页模板,首先是一个静态html文件,分析这个文件 包含的.css .js img src图片 按照指定的风格存储,最关键的是要实现css内的图片和font文件下载并替换成新的地址,再生成一个全新的css,各种逻辑错综复杂嵌套,还要实现多线程下载,最终实现了一款模板扒皮器,有了它,就能为站群系统快速做出大批量高质量的模板来了。。。